-
Pour une analyse plus pertinente et sans confusion par les outils de textométrie et le site qui nous a permis de dessiner des "nuages de mots", nous avons modifié quelques formes lexicales, celles qui nous intéressent plus particulièrement pour le projet. Le syntagme " parents hélicoptères " étant écrit de différentes manières dans nos corpus, nous avons décidé de l’uniformiser de cette façon : Helikoptereltern en allemand, et 헬리콥터부모 en coréen. De plus, le coréen étant une langue agglutinante, des particules permettant de distinguer les sujets des objets, les bénéficiaires des donnants, etc. font partie de la forme de certains mots. Nous avons donc séparé par un espace en particulier les mots parent, enfant et jeune de leur particule.
_____


Grâce au site WordArt disponible à cette adresse https://wordart.com/, nous avons créé des "nuages de mots". Il s’agit d’une silhouette représentant un nuage, composé des mots apparaissant le plus souvent dans un corpus. Le nuage de gauche est un nuage dessiné à partir de notre corpus d’articles allemands, tandis que pour celui de droite, il s’agit de notre corpus coréen. Nous avons demandé à l’outil de ne pas faire apparaître les mots outils tels que les pronoms et les prépositions, très souvent employés notamment dans le corpus allemand.
Nous pouvons déjà identifier la thématique commune de nos deux corpus : la famille. Les mots les plus importants, visibles en grand, sont " Eltern ", " Kinder " ou " Kind " en allemand, "부모 ", "아이 " et "자녀 " en coréen. Leur traduction en français sont respectivement " parents " pour " Eltern " et "부모 ", " enfants " pour " Kinder " et "아이 ", " enfant " pour " Kind " et " adolescent " pour "자녀 ". " Helikoptereltern " et " 헬리콥터부모 " signifiants tous les deux " parents hélicoptères ", sont au second plan.
La majorité des formes également présentes dans le nuage sont des verbes et des adverbes pour la part allemande, quelques noms, des particules et l’auxiliaire être [있다 ] pour le corpus coréen. Parmi ces mots, nous trouvons dans le second corpus les noms " 경우 " [occasion], " 회사 " [entreprise, lieu de travail] et " 양육 " [élevage, éducation]. Dans le premier corpus, les adverbes " viel " [beaucoup], " gut " [bien], " mehr " [plus], " nur " [seulement] sont les plus en avant. Les verbes les plus fréquents sont machen [faire], können [pouvoir], sein [être], wollen [vouloir], leben [vivre]. Il est possible que ce dernier s’agisse en réalité du nom signifiant "la vie". Suivent ensuite des noms : " Erziehung ", " Mutter ", " Sohn " et " Schule ". Ils peuvent être traduits respectivement par éducation, mère, fils et école.
 votre commentaire
votre commentaire
-
Avec les codes mises en oeuvres par Kristen, j'ai aussi crée les corpus pour le chinois et le français.
Lors du nettoyage, j'ai cependant rencontré un problème: il restait des liens d'images sous la forme [ titredel'image . png ] , [ titredel'image . jpg ] ou [ titredel'image.jpeg ].
Je les ai donc supprimé manuellement avec l'aide de la fonction "recherche" de notepad++.
Après cela, j'ai fait des nuages de mots avec Word Art.
Nuage de mots du corpus chinois:

Nuage de mots du corpus français (après la suppression de stop word tel que "le", "la", "ce", "cette", "de", "du", présent en grand nombre dans le corpus, rendant le nuage de mots moins révélatif):

On remarque beaucoup de point commun entre ces deux nuages de mots. Il y a "parent" (父母,家长), "hélicoptère" (直升机) "enfant" (孩子), "vie" (生活), "moi" (自己), "peut"(可以), "comment" (什么), "mère"(妈妈), "éducation" (教育), bébé (宝宝). Ces ressemblances entre ces deux corpus sont normales, puisqu'ils parlent tous tous des "parents hélicoptères", désignant des parents qui "plane" au dessus de leur enfant pour le guider vers le "meilleur" avenir qui soit.
Cependant, le corpus français se préoccupe plus de la "famille", de la "France". Mais aussi de la "santé", du "COVID". On peut donc supposer que le corpus français fait référence au concept des "parents hélicoptères" de France, remis au goût du jour avec le Covid et le premier confinement (avec les cours en distenciel depuis la maison, etc.).
De son côté, le corpus chinois se préoccupe de la Chine (中国), des Etats-Unis D'Amérique (美国). En effet, le terme "parent hélicoptère" a été théorisé en Amérique par Foster Cline et Jim Fay en 1990, avant d'être utilisé un peu partout dans le monde dont la Chine. On peut supposer également que le corpus chinois fait une comparaison de ce phénomène entre la Chine et l'Amérique.
De plus, le corpus chinois évoque possiblement les problèmes éventuelles engendrés par ce phénomène : 问题 (question, problème),过度 (excessif),学习 (étude scolaire),独立 (solitude),帮助 (aide, aider).
votre commentaire
-
Nous sommes parvenus à écrire deux scripts bash, l'un servant à nettoyer nos articles de chevrons inutiles (< et >), et l'autre créant un fichier corpus pour chaque langue, les articles annotés par <T = nom_fichier></T>.
Nous avons donc créé deux dossiers corpus dans le dossier PROJET-MOT-SUR-LE-WEB, appelés CORPUS-DE et CORPUS-KOR, puis nous avons copié les articles en UTF-8 dans le dossier correspondant à la langue. Les commandes sont les suivantes :
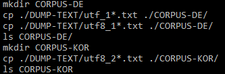
Pour effacer les chevrons, nous avons utilisé la commande tr et enregistré les articles nettoyés sous un autre nom, car autrement les données sont perdues.
Nous pouvons appeler le script de cette façon : bash ./PROGRAMMES/chevrons.sh ./CORPUS-DE
Le deuxième script peux être utilisé de cette façon : bash ./PROGRAMMES/corpus.sh DE
Seulement un argument est a donner en ligne de commande, pour le premier script, il s'agit du répertoire corpus que nous voulons traité ; pour le deuxième, il s'agit de la langue : DE pour l'allemand, KOR pour le coréen.
votre commentaire
-
Nous avons récupéré le contenu textuel de nos URLs, ainsi que le contexte où apparaît le motif que nous cherchons ("Helikopter-Eltern|헬리콥터 부모") et les bigrammes de chaque texte.
La prochaine grande partie consiste en l'écriture de fichiers, un par langue, à partir des textes obtenus. Chaque article composera une "partie" de ces corpus.
Le but de cette opération est de permettre à un outil d'analyse texto-métrique tel que iTrameur (lien vers le site), de sectionner les corpus pour une analyse pertinente. Nous allons donc entourer chaque article des balises <partie=?></partie> où ? est le numéro de la partie.
Il faut pourtant remarquer que les fichiers obtenus par dump (utf8_1-1.txt comme exemple) peuvent contenir des chevrons '<' ou '>' qui perturberont l'outil d'analyse lors de la définition des parties du corpus. Nous voulons donc trouver une manière de les enlever grâce à un script bash, avant d'ajouter les balises <partie=?></partie>.
Pour identifier s'il existe encore des chevrons dans les textes, la commande egrep est utile. La commande suivante retrouve tous les chevrons présents dans les fichiers textes dont le nom commence par "utf8_".
echo "<|>" utf8_*.txt La prochaine commande permet d'effacer chaque occurrence du motif recherché :
tr -d "<|>" < utf8_*.txt Nous avons essayé d'écrire un script à partir de ça pour chercher les occurrences de chevrons, qui n'a pour l'instant pas été concluant.
fichiersDump=$1;# argument du script, peut être « ./DUMP-TEXT/utf8_*.txt »
for file in $(ls $fichiersDump)
do
echo $file;
egrep -o "<|>" $file;
done;
Ce script, sensé passer par tous les fichiers dont le nom commence par "utf8_", ne donne que le premier fichier (utf8_1-1.txt).

Une autre façon de supprimer les chevrons serait de faire la commande tr sur chaque fichier séparément à la ligne de commande, ou de continuer dans le script précédent.
2 commentaires
-
A la séance de cours du 25 novembre, nous avons reprit le programme pour parvenir à la version finale. Nous nous étions arrêtés au traitement des URLs encodées en UTF-8.
Cette fois-ci, nous avons ajouté le traitement de données qui ne sont pas en UTF-8. Pour gagner du temps et avoir une meilleure lisibilité du script, nous avons fait des commandes de récupération des pages, de calcul de bigrammes et de recherche de contexte autour du motif choisi une fonction que nous pourrons appeler plusieurs fois. Ci-dessous la nouvelle fonction, que nous avons placé au début du script, après la déclaration des arguments. "traitementURL" est le nom de cette fonction.
traitementURL()
(
# on récupère le contenu de la page
lynx -dump -nolist -assume_charset="UTF-8" -display_charset="UTF-8" "./PAGES-ASPIREES/url_$numTable-$compteur.html" > ./DUMP-TEXT/"utf8_$numTable-$compteur".txt;
# puis on compte les occurences de notre motif
numMotif=$(egrep -o -i $motif ./DUMP-TEXT/"utf8_$numTable-$compteur".txt | wc -l);
# construction de morceaux de corpus
egrep -C 2 -i "$motif" ./DUMP-TEXT/"utf8_$numTable-$compteur".txt > ./CONTEXTES/"utf8_$numTable-$compteur".txt;
# donner à voir ces contextes en HTML
perl ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/minigrepmultilingue.pl "UTF-8" ./DUMP-TEXT/"utf8_$numTable-$compteur".txt ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/motif-2020.txt;
# sauvegarde du résultat
mv resultat-extraction.html ./CONTEXTES/"url_$numTable-$compteur".html;
# index hierarchique de chaque DUMP
egrep -i -o "\w+" ./DUMP-TEXT/"utf8_$numTable-$compteur".txt | sort | uniq -c | sort -r -n -s -k 1,1 > ./DUMP-TEXT/"index_$numTable-$compteur".txt;
# calcul de bigrammes
tr " " "\n" < ./DUMP-TEXT/"utf8_$numTable-$compteur".txt | tr -s "\n" | egrep -v "^$" > index1.txt;
tail -n +2 index1.txt > index2.txt; # on efface la 1ère ligne
paste index1.txt index2.txt | sort | uniq -c | sort -r -n -s -k 1,1 -r > ./DUMP-TEXT/"bigrammes_$numTable-$compteur".txt;
# écriture dans le tableau
echo "<tr><td>$compteur</td><td><a target=\"_blank\" href=\"$line\">$line</a></td><td>$codehttp</td>
<td><a href=\"../PAGES-ASPIREES/url_$numTable-$compteur.html\">PA $compteur</a></td>
<td><a href=\"../DUMP-TEXT/url_$numTable-$compteur.txt\">Dump $compteur</a></td><td>$encodageURL</td>
<td>$numMotif</td><td><a href=\"../CONTEXTES/utf8_$numTable-$compteur.txt\">Contexte $compteur</a></td>
<td><a href=\"../CONTEXTES/url_$numTable-$compteur.html\">Contexte $compteur</a></td>
<td><a href=\"../DUMP-TEXT/index_$numTable-$compteur.txt\">Index $compteur</a></td>
<td><a href=\"../DUMP-TEXT/bigrammes_$numTable-$compteur.txt\">Bigrammes $compteur</a></td></tr>" >> $tableau;
)Pour pouvoir travailler avec les pages web qui sont d'un autre encodage que UTF-8, nous avons converti l'encodage en UTF-8 grâce à la commande iconv : iconv -f $encodageURL -t UTF-8 ./DUMP-TEXT/"utf8_$numTable-$compteur".txt;. Pour ne pas générer d'erreur, il est nécessaire de vérifier si le nom de l'encodage est présent dans la liste de ceux supportés par iconv.
if [[ $encodageURL != "" ]]
then
reponse=$(iconv -l | egrep "$encodageURL")
if [[ $reponse != "" ]]
then
iconv -f $encodageURL -t UTF-8 ./DUMP-TEXT/"utf8_$numTable-$compteur".txt;
traitementURL;
else
echo "<tr><td>$compteur</td><td><a target=\"_blank\" href=\"$line\">$line</a></td><td>$codehttp</td><td><a href=\"../PAGES-ASPIREES/url_$numTable-$compteur.html\">PA $compteur</a></td><td> - </td><td>$encodageURL</td><td>??</td><td>??</td><td>??</td><td>??</td><td>??</td></tr>" >> $tableau;
fi
else
encodageExtrait=$(./PROGRAMMES/detect-encoding/detect-encoding.exe ./PAGE-ASPIREES/"url_$numTable-$compteur".html | tr -d "\n" | tr -d "\r");
reponse=$(iconv -l | egrep "$encodageExtrait");
if [[ $response != "" ]]
then
iconv -f $encodageURL -t UTF-8 ./DUMP-TEXT/"utf8_$numTable-$compteur".txt;
traitementURL;
else
echo "<tr><td>$compteur</td><td><a target=\"_blank\" href=\"$line\">$line</a></td><td>$codehttp</td><td><a href=\"../PAGES-ASPIREES/url_$numTable-$compteur.html\">PA $compteur</a></td><td> - </td><td>$encodageURL</td><td>??</td><td>??</td><td>??</td><td>??</td><td>??</td></tr>" >> $tableau;
fi
fiSi le script ne parvient toujours pas à détécter l'encodage de la page, nous devons appeler un logiciel déjà existant - que nous avons récupéré dans le site du cours - permettant de s'assurer de bien le détécter (encodageExtrait=$(./PROGRAMMES/detect-encoding/detect-encoding.exe ./PAGE-ASPIREES/"url_$numTable-$compteur".html | tr -d "\n" | tr -d "\r");).
Malgré les modifications apportées, il semble y avoir encore quelques soucis d'encodage :
 votre commentaire
votre commentaire Suivre le flux RSS des articles Suivre le flux RSS des commentaires
Suivre le flux RSS des articles Suivre le flux RSS des commentaires






|
|
|
|