-
Journal de Kirsten BERLAND
Bienvenue sur la rubrique du Journal de Kirsten Berland. Vous y trouverez les exercices a faire à la maison en rapport avec le cours de Programmation et Projet encadré.
-
Par kirstenb le 21 Décembre 2020 à 16:07
Nous sommes parvenus à écrire deux scripts bash, l'un servant à nettoyer nos articles de chevrons inutiles (< et >), et l'autre créant un fichier corpus pour chaque langue, les articles annotés par <T = nom_fichier></T>.
Nous avons donc créé deux dossiers corpus dans le dossier PROJET-MOT-SUR-LE-WEB, appelés CORPUS-DE et CORPUS-KOR, puis nous avons copié les articles en UTF-8 dans le dossier correspondant à la langue. Les commandes sont les suivantes :
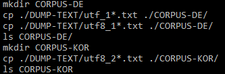
Pour effacer les chevrons, nous avons utilisé la commande tr et enregistré les articles nettoyés sous un autre nom, car autrement les données sont perdues.
Nous pouvons appeler le script de cette façon : bash ./PROGRAMMES/chevrons.sh ./CORPUS-DE
Le deuxième script peux être utilisé de cette façon : bash ./PROGRAMMES/corpus.sh DE
Seulement un argument est a donner en ligne de commande, pour le premier script, il s'agit du répertoire corpus que nous voulons traité ; pour le deuxième, il s'agit de la langue : DE pour l'allemand, KOR pour le coréen.
 votre commentaire
votre commentaire
-
Par kirstenb le 8 Décembre 2020 à 14:59
Nous avons récupéré le contenu textuel de nos URLs, ainsi que le contexte où apparaît le motif que nous cherchons ("Helikopter-Eltern|헬리콥터 부모") et les bigrammes de chaque texte.
La prochaine grande partie consiste en l'écriture de fichiers, un par langue, à partir des textes obtenus. Chaque article composera une "partie" de ces corpus.
Le but de cette opération est de permettre à un outil d'analyse texto-métrique tel que iTrameur (lien vers le site), de sectionner les corpus pour une analyse pertinente. Nous allons donc entourer chaque article des balises <partie=?></partie> où ? est le numéro de la partie.
Il faut pourtant remarquer que les fichiers obtenus par dump (utf8_1-1.txt comme exemple) peuvent contenir des chevrons '<' ou '>' qui perturberont l'outil d'analyse lors de la définition des parties du corpus. Nous voulons donc trouver une manière de les enlever grâce à un script bash, avant d'ajouter les balises <partie=?></partie>.
Pour identifier s'il existe encore des chevrons dans les textes, la commande egrep est utile. La commande suivante retrouve tous les chevrons présents dans les fichiers textes dont le nom commence par "utf8_".
echo "<|>" utf8_*.txt La prochaine commande permet d'effacer chaque occurrence du motif recherché :
tr -d "<|>" < utf8_*.txt Nous avons essayé d'écrire un script à partir de ça pour chercher les occurrences de chevrons, qui n'a pour l'instant pas été concluant.
fichiersDump=$1;# argument du script, peut être « ./DUMP-TEXT/utf8_*.txt »
for file in $(ls $fichiersDump)
do
echo $file;
egrep -o "<|>" $file;
done;
Ce script, sensé passer par tous les fichiers dont le nom commence par "utf8_", ne donne que le premier fichier (utf8_1-1.txt).

Une autre façon de supprimer les chevrons serait de faire la commande tr sur chaque fichier séparément à la ligne de commande, ou de continuer dans le script précédent.
2 commentaires
-
Par kirstenb le 2 Décembre 2020 à 00:31
A la séance de cours du 25 novembre, nous avons reprit le programme pour parvenir à la version finale. Nous nous étions arrêtés au traitement des URLs encodées en UTF-8.
Cette fois-ci, nous avons ajouté le traitement de données qui ne sont pas en UTF-8. Pour gagner du temps et avoir une meilleure lisibilité du script, nous avons fait des commandes de récupération des pages, de calcul de bigrammes et de recherche de contexte autour du motif choisi une fonction que nous pourrons appeler plusieurs fois. Ci-dessous la nouvelle fonction, que nous avons placé au début du script, après la déclaration des arguments. "traitementURL" est le nom de cette fonction.
traitementURL()
(
# on récupère le contenu de la page
lynx -dump -nolist -assume_charset="UTF-8" -display_charset="UTF-8" "./PAGES-ASPIREES/url_$numTable-$compteur.html" > ./DUMP-TEXT/"utf8_$numTable-$compteur".txt;
# puis on compte les occurences de notre motif
numMotif=$(egrep -o -i $motif ./DUMP-TEXT/"utf8_$numTable-$compteur".txt | wc -l);
# construction de morceaux de corpus
egrep -C 2 -i "$motif" ./DUMP-TEXT/"utf8_$numTable-$compteur".txt > ./CONTEXTES/"utf8_$numTable-$compteur".txt;
# donner à voir ces contextes en HTML
perl ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/minigrepmultilingue.pl "UTF-8" ./DUMP-TEXT/"utf8_$numTable-$compteur".txt ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/motif-2020.txt;
# sauvegarde du résultat
mv resultat-extraction.html ./CONTEXTES/"url_$numTable-$compteur".html;
# index hierarchique de chaque DUMP
egrep -i -o "\w+" ./DUMP-TEXT/"utf8_$numTable-$compteur".txt | sort | uniq -c | sort -r -n -s -k 1,1 > ./DUMP-TEXT/"index_$numTable-$compteur".txt;
# calcul de bigrammes
tr " " "\n" < ./DUMP-TEXT/"utf8_$numTable-$compteur".txt | tr -s "\n" | egrep -v "^$" > index1.txt;
tail -n +2 index1.txt > index2.txt; # on efface la 1ère ligne
paste index1.txt index2.txt | sort | uniq -c | sort -r -n -s -k 1,1 -r > ./DUMP-TEXT/"bigrammes_$numTable-$compteur".txt;
# écriture dans le tableau
echo "<tr><td>$compteur</td><td><a target=\"_blank\" href=\"$line\">$line</a></td><td>$codehttp</td>
<td><a href=\"../PAGES-ASPIREES/url_$numTable-$compteur.html\">PA $compteur</a></td>
<td><a href=\"../DUMP-TEXT/url_$numTable-$compteur.txt\">Dump $compteur</a></td><td>$encodageURL</td>
<td>$numMotif</td><td><a href=\"../CONTEXTES/utf8_$numTable-$compteur.txt\">Contexte $compteur</a></td>
<td><a href=\"../CONTEXTES/url_$numTable-$compteur.html\">Contexte $compteur</a></td>
<td><a href=\"../DUMP-TEXT/index_$numTable-$compteur.txt\">Index $compteur</a></td>
<td><a href=\"../DUMP-TEXT/bigrammes_$numTable-$compteur.txt\">Bigrammes $compteur</a></td></tr>" >> $tableau;
)Pour pouvoir travailler avec les pages web qui sont d'un autre encodage que UTF-8, nous avons converti l'encodage en UTF-8 grâce à la commande iconv : iconv -f $encodageURL -t UTF-8 ./DUMP-TEXT/"utf8_$numTable-$compteur".txt;. Pour ne pas générer d'erreur, il est nécessaire de vérifier si le nom de l'encodage est présent dans la liste de ceux supportés par iconv.
if [[ $encodageURL != "" ]]
then
reponse=$(iconv -l | egrep "$encodageURL")
if [[ $reponse != "" ]]
then
iconv -f $encodageURL -t UTF-8 ./DUMP-TEXT/"utf8_$numTable-$compteur".txt;
traitementURL;
else
echo "<tr><td>$compteur</td><td><a target=\"_blank\" href=\"$line\">$line</a></td><td>$codehttp</td><td><a href=\"../PAGES-ASPIREES/url_$numTable-$compteur.html\">PA $compteur</a></td><td> - </td><td>$encodageURL</td><td>??</td><td>??</td><td>??</td><td>??</td><td>??</td></tr>" >> $tableau;
fi
else
encodageExtrait=$(./PROGRAMMES/detect-encoding/detect-encoding.exe ./PAGE-ASPIREES/"url_$numTable-$compteur".html | tr -d "\n" | tr -d "\r");
reponse=$(iconv -l | egrep "$encodageExtrait");
if [[ $response != "" ]]
then
iconv -f $encodageURL -t UTF-8 ./DUMP-TEXT/"utf8_$numTable-$compteur".txt;
traitementURL;
else
echo "<tr><td>$compteur</td><td><a target=\"_blank\" href=\"$line\">$line</a></td><td>$codehttp</td><td><a href=\"../PAGES-ASPIREES/url_$numTable-$compteur.html\">PA $compteur</a></td><td> - </td><td>$encodageURL</td><td>??</td><td>??</td><td>??</td><td>??</td><td>??</td></tr>" >> $tableau;
fi
fiSi le script ne parvient toujours pas à détécter l'encodage de la page, nous devons appeler un logiciel déjà existant - que nous avons récupéré dans le site du cours - permettant de s'assurer de bien le détécter (encodageExtrait=$(./PROGRAMMES/detect-encoding/detect-encoding.exe ./PAGE-ASPIREES/"url_$numTable-$compteur".html | tr -d "\n" | tr -d "\r");).
Malgré les modifications apportées, il semble y avoir encore quelques soucis d'encodage :
 votre commentaire
votre commentaire
-
Par kirstenb le 1 Décembre 2020 à 23:51
L'écriture de la suite du script Bash sur le traitement de nos URLs consiste au repérage du motif, thème de notre projet.
Premièrement, nous cherchons a récupérer deux lignes avant le motif, et deux lignes après, quelque soit la casse de l'occurrence. Nous sauvegardons ces occurrences et leur contexte dans un fichier texte.
# construction de morceaux de corpus
egrep -C 2 -i "$motif" ./DUMP-TEXT/"utf8_$numTable-$compteur".txt > ./CONTEXTES/"utf8_$numTable-$compteur".txt;Grâce à perl et à un logiciel écrit par un ancien étudiant, "Mini-grep-multilingue", nous enregistrons les contextes dans un fichier HTML. Pour cette étape, il faut au préalable créer un fichier "motif-2020.txt" dans lequel le script écrira le motif : echo "MOTIF=$motif" > ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/motif-2020.txt;.
# donner à voir ces contextes en HTML
perl ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/minigrepmultilingue.pl "UTF-8" ./DUMP-TEXT/"utf8_$numTable-$compteur".txt ./PROGRAMMES/minigrepmultilingue-v2.2-regexp/motif-2020.txt;
# sauvegarde du résultat
mv resultat-extraction.html ./CONTEXTES/"url_$numTable-$compteur".html;Le programme de "Mini-grep-multilingue" produit un fichier dans lequel sont marquées les occurrences d'un motif dans sa ligne. La particularité de ce logiciel est qu'il est très efficace pour les langues non-occidentales.
Après nous être occupés du contexte, nous demandons d'enregistrer dans un nouveau fichier l'index des mots de la page, c'est-à-dire le nombre d'apparition associé au mot.
# index hierarchique de chaque DUMP
egrep -i -o "\w+" ./DUMP-TEXT/"utf8_$numTable-$compteur".txt | sort | uniq -c | sort -r -n -s -k 1,1 > ./DUMP-TEXT/"index_$numTable-$compteur".txt;Ensuite, nous avons cherché les bigrammes (ensemble de deux mots) en récupérant la liste des mots de la page, et en copiant à côté la même liste, la première ligne suppprimée.
# calcul de bigrammes
tr " " "\n" < ./DUMP-TEXT/"utf8_$numTable-$compteur".txt | tr -s "\n" | egrep -v "^$" > index1.txt;
tail -n +2 index1.txt > index2.txt; # on efface la 1ère ligne
paste index1.txt index2.txt | sort | uniq -c | sort -r -n -s -k 1,1 -r > ./DUMP-TEXT/"bigrammes_$numTable-$compteur".txt;Il est possible de télécharger sur ce site http://www.tal.univ-paris3.fr/cours/minigrepmultilingue.htm le dossier contenant tout ce dont nous avons besoin pour se servir de "Mini-grep-multilingue".
Vous pouvez voir ici le nouveau script « table_url.sh », et le tableau « tableau_url.html » donné avec nos fichiers d'URLs pour le motif "Helikopter-Eltern|헬리콥터 부모".
votre commentaire
-
Par kirstenb le 24 Novembre 2020 à 15:03
Une partie de notre projet consiste en la récupération des données sur lesquelles nous allons travailler plus tard. L’objectif de cette étape est d’obtenir un corpus de textes à partir de sites internet que nous avons choisis. Nous avons décidé de nous concentrer sur des articles de presse de différentes langues contenant l’expression « parents hélicoptères ». Alexandra s’occupe de sites en chinois et en français, tandis que je travaille sur des sites allemands et coréens. Parmi les journaux en allemand, Die Zeit a par exemple été pris en compte, et le journal Chosun était une source pour le coréen. Les adresses URL des articles que nous avons choisis ont été enregistrés chacun dans un fichier texte, en fonction de la langue. (Disponibles ici : « german.txt » et là : « korean.txt »)
Pour cette étape importante de notre projet, nous écrivons un programme en Bash avec nos enseignants durant les séances de cours. Ce programme nous permet de traiter tous les fichiers énumérant les sites que nous avons choisis, automatiquement et d’une seule traite. Nous ne sommes pas encore arrivés à la version finale du programme, mais nous devrions l’avoir bientôt.
Tout d’abord, nous souhaitons que les progrès du traitement des sites soient enregistrés dans autant de tableaux HTML que de langues – plus précisément de fichiers contenant les listes d’URLs. Pour ce faire, nous définissons des arguments : le dossier contenant les fichiers et le nom du fichier HTML. Pour que nous obtenions réellement un fichier HTML montrant des tableaux, le programme doit écrire des balises pertinentes dans le fichier.
Ensuite, nous passons au traitement des listes d’URLs. Chaque résultat sera inscrit dans les tableaux. La première colonne est le numéro de l’URL – la ligne du fichier pour ce site. La deuxième est l’adresse elle-même. Pour le moment, nous n’avons eu aucun souci pour les sites allemands et coréens en ce qui concerne la récupération de ces deux valeurs.
Nous voulons « aspirer » les sites grâce à la commande curl et savoir si « l’aspiration » c’est correctement passé. On regarde alors le code HTTP produit lors de la commande, et le notons dans le tableau. Si le code est 200, cela s’est bien passé. Sinon, la page n’a pas pu être aspirée. Dans le cas des sites en allemand, 3 sites n’ont pu être récupérés, et 4, des sites en coréen. Leur code HTTP varient entre 400, 302, 403 et 410 (respectivement : syntaxe de la requête erronée, restriction temporaire, accès refusé et ressource plus disponible).
Si les pages sont bien aspirées, nous souhaitons connaître leur encodage, et s’il s’agit de l’UTF-8, le programme doit récupérer le contenu textuel et le sauvegarder dans des fichiers textes. Toutes les pages en allemand qui ont pu être récupérées, ont été encodées en UTF-8, à part une en ISO-8859-1. Quatre pages sont dans le même cas en coréen, mais sur cinq pages, l’encodage n’a pas été reconnu. Quelques pages ont également été encodées en EUC-KR. Il se trouve que la présentation de l’encodage dans le code HTML varie parfois, et il est même possible de trouver plusieurs fois le mot « charset » dans la balise <head> de la page. Ce mot permet d’identifier le système d’encodage.
Finalement, nous voulons savoir combien d’occurrence du motif choisi, « parents hélicoptères » pour nous, apparaît dans chaque article. Nous avons cherché le motif en allemand, « Helikopter-Eltern », mais il existe d’autres façons de l’écrire. Bien évidemment, en ne recherchant seulement ce motif, aucune occurrence n’est observée dans les pages en coréen. Il faudra réfléchir à comment formuler un motif comprenant toutes les variations.
Pour télécharger le programme Bash, cliquer ici, et là pour voir le tableau obtenu sur les fichiers d'URLs en allemand et en coréen.
votre commentaire Suivre le flux RSS des articles de cette rubrique Suivre le flux RSS des commentaires de cette rubrique
Suivre le flux RSS des articles de cette rubrique Suivre le flux RSS des commentaires de cette rubrique




|
|
|
|