-
Création de corpus
Nous sommes parvenus à écrire deux scripts bash, l'un servant à nettoyer nos articles de chevrons inutiles (< et >), et l'autre créant un fichier corpus pour chaque langue, les articles annotés par <T = nom_fichier></T>.
Nous avons donc créé deux dossiers corpus dans le dossier PROJET-MOT-SUR-LE-WEB, appelés CORPUS-DE et CORPUS-KOR, puis nous avons copié les articles en UTF-8 dans le dossier correspondant à la langue. Les commandes sont les suivantes :
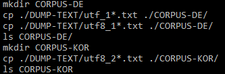
Pour effacer les chevrons, nous avons utilisé la commande tr et enregistré les articles nettoyés sous un autre nom, car autrement les données sont perdues.
Nous pouvons appeler le script de cette façon : bash ./PROGRAMMES/chevrons.sh ./CORPUS-DE
Le deuxième script peux être utilisé de cette façon : bash ./PROGRAMMES/corpus.sh DE
Seulement un argument est a donner en ligne de commande, pour le premier script, il s'agit du répertoire corpus que nous voulons traité ; pour le deuxième, il s'agit de la langue : DE pour l'allemand, KOR pour le coréen.
-
Commentaires

|
|
|
|