-
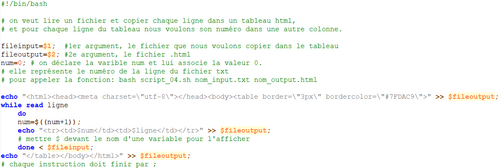
L'objectif de la séance: créer un programme qui avec une liste d'URLS, créer un tableau dans une page html. Ce tableau a trois colonnes: numéro de ligne de l'URL, lien de l'URL, ainsi qu'un lien interne vers la page html aspirée. Pour chaque fichier d'urls, il faut un tableau html.
On précise en commentaire comment exécuter le programme, puis on déclare les arguments en tant que variable dans le programme.
#!/usr/bin/bash
#bash ./PROGRAMMES/projet.sh ./URLS ./TABLEAUX/tableau.html
#input du programme : NOM DE DOSSIER est donné en premier argument
#output du programme : TABLEAU HTML est donné en second argument
dossierURL=$1;
montableau=$2;
On crée la page html avec l'entête de cette dernière:echo "<html><head><meta charset=\"utf8\"></head><body>" > $montableau; On initialise le compteur des tableau:
compteur_tableau=1; Avec une boucle for, on va ensuite parcourir la url de chaque fichier. dans cette boucle for, on va:
- Pour chaque fichier d'URLs, on va créer un nouveau tableau avec un titre
- Initialiser le compteur d'URLS
- Tant que le programme lit le fichier d'URL ligne par ligne:
- Traiter l'URL: pour le moment, cela consiste à "aspirer" la page html associé à l'URL avec la commande curl.
- Écrire dans le tableau final: le numéro de l'URL, le lien de l'URL, ainsi que le lien interne de la page aspirée
- Incrémenter le compteur d'URL
for fichier in $(ls $dossierURL);
do
echo $fichier;
echo "<table border="10px">" >> $montableau;
compteur=1;
echo "<tr><th colspan=\"3\">TABLEAU $compteur_tableau</th></tr>" >> $montableau ;
compteur_tableau=$((compteur_tableau+1));
while read ligne
do
curl $ligne -o ./PAGES-ASPRIREES/$compteur_tableau$compteur.html;
echo "<tr><td>$compteur</td><td><a href=\"$ligne\" target=\"_blank\">$ligne</a> </td><td><a href=\"../PAGES-ASPIREES/$compteur_tableau$compteur\">Page aspirée numero: $compteur_tableau$compteur</a></td></tr>" >> $montableau;
compteur=$((compteur+1));
done < ./$dossierURL/$fichier
echo "</table>" >> $montableau ;
done ;On finit la sortie de la page html:
echo "</body></html>" >> $montableau ; Pour télécharger le programme réalisé: Télécharger « projet.sh »
Attention: on remarque que certaines page html ne sont pas correctement aspirées ou ne sont pas aspirées par le programme.
 votre commentaire
votre commentaire
-
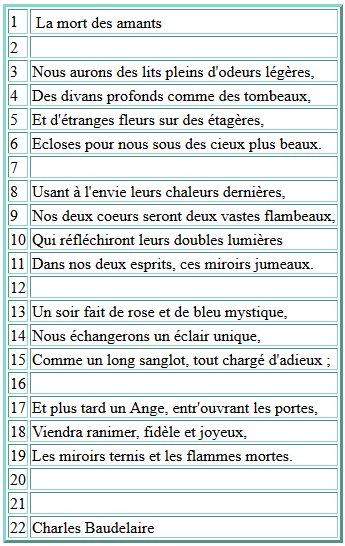
Cet exercice consiste à compléter un script Bash que nous avons écrit en cours. Ce script écrit un code html comportant un tableau. A partir d'un fichier texte renseigné par l'utilisateur, le programme lit chaque ligne et les copie dans le tableau.
Vous pouvez télécharger le script original écrit en cours ici : script_tableau01.sh et le script modifié : script_tableau02.sh.
En exécutant ce script grâce à l'instruction bash script_tableau02.sh amants-utf8.txt tableau_amants.html, nous obtenons ce tableau, visible également ici :
Nous avons trouvé le code de la couleur sur le site https://html-color-codes.info/.
votre commentaire
-
Pour pouvoir mieux intégrer ce que avons appris lors du deuxième cours, nous avons résolut les exercices sur le terminal Unix, que nous pouvons trouver à la page du cours sur iCampus et également en suivant ce lien du site Plurital.
Application 1 :
Nous avons une liste de commandes à saisir dans notre terminal de commandes. Certaines sont formulée en langage naturel.
Nous sommes placés dans le répertoire Projet_encadre, qui a pour chemin absolu /home/kirsten-gaby/Documents/M1/S1/Projet_encadre et contient le fichier cours1.odt.
Les commandes mkdir TEST1 et mkdir TEST2 exécutent la création de deux répertoires TEST1 et TEST2 dans le répertoire courant. Nous pouvons le vérifier avec la commande ls.

On nous demande ensuite de créer un répertoire « TEST 3 » sans nous donner de commande. Il faut faire attention à l’écriture, car sur le terminal, les commandes, arguments et options sont séparés par un espace. Si nous écrivons mkdir TEST 3, TEST et 3 vont être considérés comme des éléments à part. La commande est donc mkdir «TEST 3», mais nous pourrions aussi l’écrire de cette façon : mkdir TEST\ 3. Le backslash \ indique au processeur qu’il faut compter l’espace comme un caractère du nom de répertoire, et non comme un séparateur.

La commande suivante cd TEST1 nous déplace dans le répertoire TEST1, qui doit être vide.
Nous exécutons alors la commande touch vide1.txt ./TEST1/vide2.txt ../TEST2/vide3.txt. La commande touch créé un ou des fichiers vides, en fonction du nombre d’arguments. Ici, le fichier vide1.txt est créé dans le répertoire courant et le fichier vide3.txt dans le répertoire TEST2. Le fichier demandé vide2.txt ne peut être créé, car nous n’avons pas de dossier TEST1 dans le répertoire courant, le terminal nous envoie ce message d’erreur : touch: impossible de faire un touch './TEST1/vide2.txt': Aucun fichier ou dossier de ce type.

Les commandes echo « Kirsten Berland » > vide1.txt et echo « Parents hélicoptères » >> vide1.txt ajoutent du contenu au fichier vide1.txt. Avec cat, nous pouvons voir son contenu. Les deux chevrons >> permettent de ne pas écraser le contenu déjà existant du fichier.

mv vide1.txt jenesuisplusvide.txt déplace vide1.txt en le renommant jenesuisplusvide.txt sur le répertoire courant. Nous n’avons donc plus vide1.txt mais jenesuisplusvide.txt dans TEST1. La commande cp permet de copier un fichier, et de renommer la copie si nous le voulons. Nous avons donc un nouveau fichier dans TEST1 et dans TEST2.

Nous faisons ensuite cat > toto.txt, qui nous demande de saisir du texte. Ce texte sera écrit dans le fichier nouvellement créé toto.txt.

Avec ls > liste.txt, nous inscrivons le contenu du répertoire courant dans le nouveau fichier liste.txt. ls >> liste.txt écrit une nouvelle fois le contenu du répertoire à la suite de la première liste, dont le fichier liste.txt lui-même.
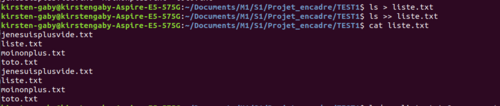
La commande lsd n’existant pas, le ‘2>’ de lsd >> liste.txt 2> erreur.txt permet de créer le fichier erreur.txt et d’y inscrire le message d’erreur émise.

Le contenu du répertoire TEST1 est copié deux fois dans un fichier liste.txt du répertoire TEST2.

Les deux commandes suivantes rm vide2.txt et rmdir ../TEST3 sensées supprimer vide2.txt et le dossier TEST3, mais ceux-ci n’existant pas, nous recevons un message d’erreur.

Application 2 :
On nous demande d'écrire l'instruction pour compter le nombre de fichiers présent dans notre répertoire de travail. Nous utilisons la commande ls, qui liste le contenu du répertoire courant, et wc, qui compte le nombre de mots, de lignes et de caractères d'un fichier.
Pour que wc agisse sur le résultat de ls, nous utilisons le pipeline |. La liste donnée par ls est enregistrée en tant qu'argument de wc. L'option -l est ajoutée car nous ne voulons voir que le nombre de fichiers du répertoire.
Nous avons donc ceci : ls | wc -l
Cette instruction compte aussi les répertoires, s'il y en a. Nous pouvons donc la réécrire comme ceci : ls *.* | wc -l, l'expression '*.*' cherchant tous les noms comportant un point, les extensions de noms commençant par un point.
Dans la deuxième question, il s'agissait d'écrire une instruction comptant le nombre de fichiers dans TEST2.
Rappelons nous que nous nous situons dans le répertoire TEST1. L'instruction devient : ls *.* | wc -l ../TEST2. Nous avons donc trois fichiers dans TEST2 : vide3.txt, jenesuispasvide.txt et liste.txt.
votre commentaire
-
Exercice: à partir du script fait en cours, y ajouter une colonne supplémentaire au tableau final et y insérer le numéro de la ligne lue.

Télécharger le script bash exercice2.sh
Le résultat de ce script bash sur amants-utf8.txt:

Télécharger « tableau-exo.html »
On veut maintenant supprimer les lignes vides:

 2 commentaires
2 commentaires
-
Pour les manipulations suivantes, on se place dans le répertoire "Projet", dont le chemin absolu est /home/tim/Documents/Projet
APPLICATION - Les entrées et les sorties -
On crée deux répertoires "TEST1" et "TEST2" avec la commande mkdir et on vérifie la création de ces répertoires avec la commande ls :

Comment créer un répertoire qui s’appellerait « TEST 3 » ?
Pour faire cela, je tape la commande mkdir 'TEST 3'. En effet, sans la mise de la quote ' , la commande mkdir comprend qu'il faut créer deux répertoires: 3 et TEST.

On se déplace maintenant dans le répertoire TEST1 avec la commande cd TEST1. On y crée trois fichiers vides avec la commande touch : touch vide1.txt vide2.txt ../TEST2/vide3.txt. On apprend par la commande man touch que la commande touch change l'horodatage des fichiers mis en arguments, mais lorsqu'on entre un arguments des fichiers non existants, elle crée des fichiers vides.

Dans le fichier vide1.txt crée, j'y écris mon nom "Alexandra LI COMBEAU LONGUET. J'y ajoute à sa suite sur la ligne suivante, le nom du projet "Les parents hélicoptères". Je vérifie que tout cela a bien été ajouté avec la commande cat vide1.txt

Avec la commande mv qui permet de bouger un fichier d'un emplacement à un autre, je renomme vide1.txt en jenesuisplusvide.txt

Je copie le fichier jenesuisplusvide.txt dans le répertoire TEST2 crée précédemment. Ensuite, je duplique le fichier jenesuisplusvide.txt répertoire TEST1.. Ce doublon est nommé moinonplus.txt

Je demande la liste des fichiers du répertoire où je suis avec la commande ls. Ensuite, dans une autre commande, je demande à ce que cela soit enregistré dans un fichier que le système va crée, nommé liste.txt.
Après cela, je demande à ce que dans ce fichier, soit ajouté à sa suite le résultat de la commande ls (qui est à nouveau exécuté).
Avec la commande less liste.txt, je visualise dans une fenêtre de lecture ce fichier.


Même si le Terminal affiche à la foit le flot de sorti et le flot d'erreur, je peux distinguer ces deux flots dans les commandes bash. Par exemple, je peux demander à ce que le résultat de la commande fictive lsd soit imprimé à la suite dans le fichier liste.txt. Si il y a une erreur, je peux demander à ce que le résultat du flot d'erreur soit enregistré dans le fichier erreur.txt: lsd >> liste.txt 2> erreur.txt

Puisque seul la liste des fichiers du répertoire TEST1 m'intéresse, j'exécute la commande ls en demandant à ce que le résultat de la commande soit imprimé dans un nouveau fichier nommé liste.txt dans le répertoire TEST2: ls > ../TEST2/liste.txt
Je demande ensuite à ce que cette liste des fichiers soit à nouveau imprimé dans le fichier existant liste.txt du répertoire TEST2: ls >> ../TEST2/liste.txt

Maintenant, je supprime les fichiers vides du répertoire TEST1 avec l'aide de la commande rm. Il y a seulement vide2.txt. Pour cela, j'exécute rm vide2.txt

Je supprime ensuite le répertoire vide 'TEST 3' avec la commande rmdir : rmdir ../TEST3

APPLICATION - Les enchaînements de commandes
Rappel : Le répertoire de travail étant le répertoire Projet, et ce dernier ne contient que les répertoires crées précédemment: TEST1 et TEST2.
Compter le nombre de fichier dans votre répertoire de travail ?
La commande wc permet de compter le nombre de mots, lignes, ainsi que les octets d'un fichier. L'option -l permet de ne compter que les lignes.
La symbole | permet de rediriger la sortie standard de la commande précédant le | à l'entrée standard le suivant.
Donc, la commande ls | wc -l permet de faire la liste des fichiers du répertoire courant puis le compter les éléments de cette même liste.
Compter le nombre de fichier dans le répertoire TEST2 ?
En procèdent de la même façon que la question précédente, on exécute la commande ls ./TEST2 | wc -l
Les résultats en image:
 votre commentaire
votre commentaire















|
|
|
|